Deep Learning versus Deep Reinforcement Learning in a Real-World Environment

I recently completed two specializations on Coursera, the Deep Learning Specialization offered by Andrew Ng and the Reinforcement Learning Specialization offered by University of Alberta (both of which I highly recommend along with Andrew Ng’s Machine Learning course for anyone looking to learn about these concepts). I was quite amazed by the capabilities of these algorithms, especially by reinforcement learning which is, in my opinion, the closest algorithm to a real AI out of those that I’ve studied. It describes an agent that learns from experience whether some action is good or bad, given a certain scenario (state). This got me thinking; How good is it really? How does it compare to deep learning? So I wanted to put both algorithms to the test.
TLDR; I ran into some unexpected obstacles with both algorithms. The solution involved training an object detection model to detect the ball. This model was used to define the states for the Reinforcement Learning. Unfortunately, this improvement was still insufficient to obtain an acceptable RL model. I did, however, identify a bunch of possible causes for the problem (too many).
The Test
My test was pretty simple. A ping pong ball is rolled on a rectangular foam board from one end to the other along the longer axis. The task is to estimate where the ball would roll to or to put it simply, catch the ball. Sounds simple enough, right? Well, I thought so too.
Testing Environment
Here’s how I built the testing environment. I mounted two small foam pillars on the left corner and right corner of the far end of the foam board. Then I fixed a servo motor on one of the pillars and a toothpick on the other. I controlled the motor using an Arduino which was connected to my laptop where all the code responsible for the predictions were running. To the motor, I fixed a pulley and I made a loop around the pulley and toothpick using a string. The servo motor I chose had an approximate range of 180 degrees and the range within which the ball was expected to be caught was approximately 18 cm. I calculated the radius of the pulley by the equations below.


An Introduction to the Algorithms
Before going into the code, I’ll give a small introduction on the two algorithms. They will be discussed further in the next section.
First, let’s talk about deep learning. This is one of the more popular algorithms for machine learning, especially because of how adaptable it is to pretty much any task. I won’t be going too deep (pun intended) into the algorithm but basically it is formed by something called a neural network which you can think of as a brain with layers and layers of brain cells (a.k.a. neurons) that are connected with neurons of adjacent layers. Each of these neurons would represent a numeric value that changes depending on the input. We can train this brain by giving it an input and telling it what the output should be. The more data we feed into it, the better it will adapt to giving the necessary output. (Note that this explanation may be over-simplified to the point where some of it may seem inaccurate or incomplete. I didn’t want to make this section too long. Feel free to ask me anything in the comment section below for clarification.)

Next we’ll talk about Reinforcement Learning. Like I said in the beginning, this algorithm learns from experience. An agent is given all the information about its environment and this information is used to make a decision on which action to take. If the action was what we wanted it to take, we give it a positive reward and vice versa. The agent will alter the parameters in its algorithm in order to maximize the said reward. Both algorithms will be discussed further when we talk about the code.
Note that I used Double Deep Q-Learning (DDQN for Double Deep Q Networks) as my reinforcement learning algorithm which is technically a combination of deep learning (DL) and one of the classic reinforcement learning (RL) algorithms, Q-Learning. I also tried using Deep Deterministic Policy Gradients (DDPG) which is like a combination of DDQN and another algorithm known as the Actor-Critic method.
The Code
I’ll start with the RL code. In DDQN, two deep neural networks are being used; one for selecting actions (online network) and one for calculating the loss function (target network) using which we’ll optimize our online network. I will not go into details on how this optimization takes place (lookup gradient descent and back propagation if you want to learn more). The online network would be periodically duplicated to form the new target network. This ensures that the model continues to improve.
The input to the network is the frame as captured by the webcam. Because the laptop webcam is at an angle to the board, instead of directly above the board, the board occupies only the bottom half of the image. Therefore, the top half of the image was cropped out, the result was resized into an 80x48 image and then converted into gray scale to improve efficiency.
I didn’t want to “reinvent the wheel” so I started with the neural network architecture used in DeepMind’s paperlink where they taught an agent to play multiple Atari games. I required a fast neural network that can estimate how good an action is (a.k.a. Q-values) accurately and this architecture had clearly proven itself before.
I did, however, alter the input image dimensions a little bit to fit the size of the image I’m generating. The original paper used an input of shape 84x84x4 (4 frames so that the neural network can predict the movement of objects accurately) while I used two 80x48 frames concatenated one on top of the other to form a single 80x96 image. I believed that 4 frames might be overkill for this simple task as I am not expecting the ball to bounce off the side.
The algorithm was allowed to choose one of three actions, to rotate the motor to 30, 90 or 150 degrees, based on where the ball was predicted to go.
I also used something known as “experience replay” (also used in the original paper). Here, we store information about the states we have already encountered such as the actions we took, rewards we got for those actions, the next state that the action led to and whether the next state is terminal. Then we sort-of “re-experience” the taken actions by selecting a random batch of “experiences” and optimizing our model based on them.
I won’t go into too much detail with regard to the DDPG method (mainly because I’m not too familiar with the algorithm yet). Basically what happens is, there is something called an actor network which chooses what action to take and a critic network which judges the action on how good it was. Then there is another pair of actor-critic networks known as the Target actor-critic networks. Like in DDQN, these are used to calculate the loss functions for the original actor network and critic network, separately. The advantage of using DDPG is that it supports continuous action spaces unlike DDQN which only supports discrete action spaces. A continuous action space is more appropriate for this because it would have an idea about facts like the left is closer to the center than it is to the right.
The DL algorithm is fairly straight forward. It consists of a single Convolutional Neural Network (CNN) which is a neural network consisting of hidden layers know as Convolutional layers. To put it simply, a convolutional layer is a layer that excels at filtering out certain characteristics of an image. I will not be going into details on how exactly this works as explaining it would require at least a couple of pages. A quick google search on “Convolutional Neural Networks” should bring up a good number of videos where it is well explained.
Attempts and Results
First I worked on the DL algorithm. Collecting data wasn’t too easy. I recorded 3 videos, consisting of me rolling the ball to the left, to the center and to the right. Afterwards, I cropped the top half of each frame (only the bottom half of the image contained the foam board), concatenated it with the frame that was 2 frames before itself and then saved this image. Next, I had to hand-pick the images that actually consisted the ball so that the algorithm knows what frames are of importance.
After collecting a satisfactory number of images (about 100 images per category), I trained the DL algorithm, giving the frame as the input and the category as the output. The category was represented as a one-hot encoded array with 3 elements. After 50 epochs (training the entire dataset 50 times) the accuracy has behaved as follows:
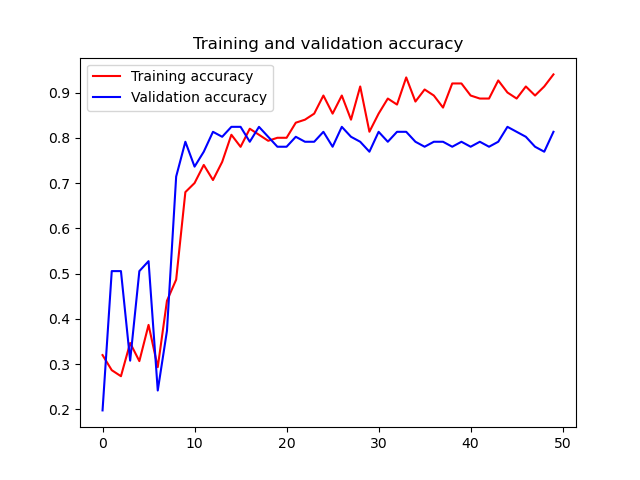
This may seem like decent improvement but the graph itself turned out to be slightly misleading. The reality was that neither of the two algorithms performed too well at test time.
The RL algorithm eventually converged to a single action, irrespective of where the ball was rolling to. For example, it started to always predict that the ball will be caught at the center, irrespective of what direction I actually rolled it towards. So I started rolling the ball more towards the other 2 directions to show the algorithm that it doesn’t always go to the center. Eventually, the algorithm started picking a single action that wasn’t the center action. Now, it was stuck picking that action. This observation brought a mistake I made to my attention: Human Bias. I had, unintentionally, caused the algorithm to think certain actions almost never result in a positive outcome, which is completely untrue.
The DL algorithm too behaved similarly. It consistently chose a single action, despite me throwing the ball.
This made me realize something; The algorithms weren’t detecting a significant enough difference between frames. The ball occupies only a few pixels out of the entire image and its presence or absence doesn’t mean much to the algorithm. Even if it did, other subtle changes in the image like the presence of my hand or a change in the background may trigger an incorrect action.
This gave me an idea. What if we use a deep learning algorithm separately to detect and locate the ball? This eliminates the problem of having to deal with unimportant pixels in the image. I decided to use this method for both the RL and DL algorithms.
I used the frames from the videos I previously recorded as data. I deleted the frames without the ball and the frames with the ball looking blurry. Then I ended up with a total of about 700 images. Next, I used LabelImg to label and draw a bounding box around the ball in all these images. Afterwards, I used Tensorflow Object Detection API to train a model that detects the ball. I won’t go into details about how this was done. You can follow this tutorial by Gilbert Tanner if you want to try it yourself.
The new DL algorithm was fairly simple. (Note that collecting data and predicting are both on the same script.)
- Collecting data: I rolled the ball many times and for each roll, I used the horizontal location of the ball in 3 consecutive frames as input and the horizontal location of the ball when the vertical location of the ball is greater than 80% as the expected output. All the data was saved in a text file. I collected about 450 rows of data in this way.
- Training data: Next, I loaded the data into memory and trained it for 100 epochs on a fairly simple deep neural network.
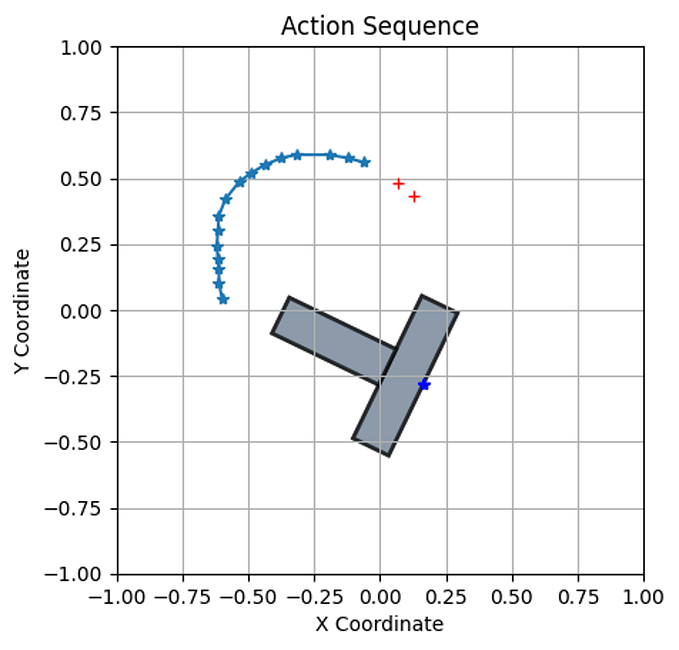
- Predicting: This, too, was done using 3 consecutive frames. The frames were selected from the center of the trajectory as it is close enough to the end so that the results are acceptably accurate, and further enough from the end such that the motor has enough time to act.

As seen from the above graph, the model has converged in a very few epochs. This implies that training any more would likely cause over-fitting and that collecting more data might help create a better model. However, I was quite satisfied with the results obtained (about +/- 5 degrees rotation accuracy), so I didn’t spend more time on it.
For the RL algorithm, I decided to consider the case where the ball was detected in consecutive frames as an episode and the case where the ball was detected at a position below 80% of the image as the end of an episode (the ball has rolled to the end). This gave the added advantage of knowing exactly when an episode begins and ends which resulted in the unnecessary frames being ignored.
Each state consisted of the horizontal location of the ball in 3 consecutive frames and the action taken was compared with the horizontal location of the ball in the final frame of the episode in order to decide what the appropriate reward should be.
Unfortunately, this too ran into the previous problem of getting biased towards a certain action. Both DDQN and DDPG algorithms faced this problem in one way or another.
The Problems
There are quite a few reasons why I probably didn’t get a satisfying result for the RL method:
- Lack of Training: I think the main reason probably was that there really wasn’t enough training. Deepmind’s paper trained their algorithm for about 50 million frames which equates to about 38 days of game experience. It was naive of me to expect my algorithm to perform any better than random, even for a simple case such as this. I do, however, still believe that achieving this is within realistic bounds, given that the rest of the problems were resolved. An advantage with simulating an environment is that we can stay hands-off with it while it is being trained. So, in real-world environments, unless we build a system to automate the ball returning to the starting point and being projected in a random direction, we’ll have to intervene at the end of each episode, which is pretty much every 2 to 4 seconds. This brings me to my next problem.
- Short Episode Length: The episodes were too short as the ball takes only a few seconds to roll from one end to the other. I had no choice but to consider each episode to be a single state which leads to a terminal state after a single action. This resulted in very little data being produced after every episode. The solution would probably be to build a longer foam board.
- Foam board Surface: Although the board seemed smooth at a distance, there were a lot of irregularities upon closer inspection. This resulted in many cases where the ball moved in an unpredictable curved path. The fact that the ball was a ping pong ball, which has very little weight, caused the effects from irregularities to be further amplified. This made it even harder for the algorithms to understand the environment.
- Camera Angle: Another major problem that may have caused the unsatisfying results is the angle at which the camera observes the foam board. Because I’m using a laptop webcam as the camera, the only way I was able to get a decent enough view of the board, was by closing the laptop to an acute angle. The fact that this was an angled view instead of a top down view resulted in the far end of the board to appear smaller. Therefore, even a ball rolling straight appeared as an angled trajectory to the camera. The algorithm may still be able to overcome this problem, given enough training.

I will be reattempting the RL problem as soon as I find a proper webcam or some way to position a camera above the board. The board, too, should be swapped for one that is longer and consisting of a smoother, more uniform surface.
I’m not really expecting anyone to reach this point of the article but if you did, I really hope you gained something out of the little success I had and the many failures I encountered. Stay safe and thank you for reading!